Deep Residual Learning for Image Recognition
Deep Residual Learning for Image Recognition
Background
이미지 분류 모델(CNN)은 층이 깊어질수록 저수준의 특징(선, 면)부터 고수준의 추상적 특징(이목구비, 물체의 형태)까지 단계적으로 학습할 수 있다. 따라서 이론적으로는 층이 깊을수록 모델의 표현력이 좋아져야 한다.
하지만 실제로는 레이어 층이 깊어질수록 오히려 학습 오차가 높아지는 ‘퇴화(Degradation) 문제’가 발생한다. 논문에서는 기존 모델에 항등 매핑(Identity Mapping) 레이어를 추가한 실험을 통해, 모델이 ‘아무것도 하지 않는 법’조차 배우지 못할 만큼 최적화가 어려워짐을 증명했다.
모델이 디테일 해지기 위해선 레이어층이 깊어져야 하는데, 그러면 성능이 저하되는 반작용이 이뤄지는 것이다.
왜그런지 살펴보자면, 전체 모델은 다음과 같이 나타낼 수 있다. \(\begin{align} L &= \mathcal{H}_{T}(\mathcal{H}_{T-1}( \cdots \mathcal{H}(x))) \\ x_{t} &= \mathcal{H}_{t}(x_{t-1}) = \text{ReLU}(W_{t}x_{t-1}) \end{align}\) 이때 $\mathcal{H}$는 임의의 함수이고, 편향항은 표기적 간편을 위해 생략하였다.
레이어 층이 깊어질수록, 모델 출력의 헤시안의 값에도 그만큼 영향을 주는 가중치의 수가 많아진다.
레이어의 연쇄적인 곱으로 인해 곡률의 최대치($\lambda_{\max}$)와 최소치($\lambda_{\min}$)의 격차가 벌어지면, 손실 지형이 더 복잡해진다는 것인데, 이는 층이 깊어질수록 손실 지형에서 최적의 부분이 그만큼 축소된다는 점과 맞물려, 결국 경사하강법을 통한 학습이 어려워지게끔 한다.
Deep Residual Learning
이에 논문에서는 다음과 같은 잔차 학습(Redidual Learning)프레임워크를 제시하였다. .png) \(\begin{align} \mathcal{H}(x) \to \mathcal{F}(x) + x \end{align}\)
\(\begin{align} \mathcal{H}(x) \to \mathcal{F}(x) + x \end{align}\)
즉 기존 맵핑 $\mathcal{H}(x)$를 학습하는 것이 아니라, 입력값과 출력의 차이인 $\mathcal{F}(x)=\mathcal{H}(x)-x$를 학습하는 것이다.
왜 이렇게 하면 학습이 기존보다 잘되는가?

위 영상에서 볼 수 있듯, 다음과 같이 극단적인 예시로 항등 매핑을 살펴보자. \(\begin{align} x_t &= \text{ReLU}(W_{t}x_{t-1} + x_{t-2}) \\ W_t \to 0 &\implies \text{ReLU}(0 \cdot x_{t-1} + x_{t-2}) = \text{ReLU}(x_{t-2}) = x_{t-2} \end{align}\) 항등 매핑의 학습에선 가중치 $W_t$를 $0$으로 수렴하도록 학습하고 단순히 입력값 $x_{t-2}$를 넘김으로써 수행한다.
이와 반대로 기존 매핑 $\mathcal{H}(x) = x$를 학습하기 위해서는 다음과 같다. \(\begin{align} x_t &= \text{ReLU}(W_tx_{t-1}) = \text{ReLU}(W_t(W_{t-1}x_{t-2})) = x_{t-2} \end{align}\) 저 식을 만족시키기 위해선 $W_{t-1}, W_{t}$ 값의 조합으로 항등 매핑이 되어야 한다. 직관적으로도 앞선 잔차 학습의 경우보다 어려움을 확인할 수 있고, 앞서 살펴봤듯이 이러한 가중치 행렬의 조합으로 손실 지형이 복잡하게 되는 원인이 된다.
지금은 극단적인 예시로 항등 매핑의 경우에서 설명하였지만, 논문은 설령 정답이 완전한 항등 매핑이 아닐지라도, 정답 함수가 0(Zero mapping)보다는 항등 매핑에 더 가까울 것이라고 가정한다. $\mathcal{H}(x) \approx x$ 로 처음부터 학습하는 것보단, $\mathcal{F}(x) + x \approx x \to \mathcal{F}(x) \approx 0$ 으로 학습 대상의 범위를 줄인다는 점에서 학습이 쉬워진다고 하였다.
Implementation
직접 살펴보기 위해서, CIFAR-10 데이터셋에서 학습을 진행해보았다. 모델의 구조는 논문에서 나와있듯이, 다음과 같다.
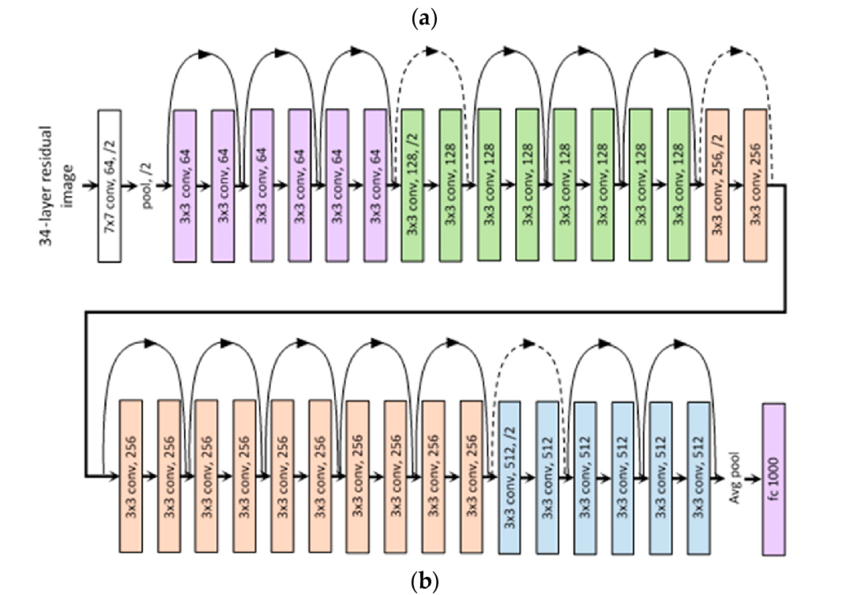
이를 CIFAR-10의 $32 \times 32$ 이미지에 맞추어 다음과 같이 논문에선 모델의 구조를 정의한다.
| output map size | $32 \times 32$ | $16 \times 16$ | $8 \times 8$ |
|---|---|---|---|
| # layers | $1+2n$ | $2n$ | $2n$ |
| # filters | $16$ | $32$ | $64$ |
총 $6n + 1$개의 컨볼루션 레이어와, 마지막 출력에 GAP(Global Average Pooling) 레이어와 FC 레이어를 통해 CIFAR-10의 10개의 클래스에 대한 모델의 출력을 반환한다.
하이퍼 파라미터는 대부분 논문을 그대로 사용하였다.
차이점으로는 총 60 에포크동안 학습을 진행하고, 30, 45 에포크에서 학습률이 $\gamma = 0.1$ 만큼 조정되도록 하였고, $n = [3,9]$인 경우에 대해서만 학습을 진행하고 비교하였다.
| PlainNet | ResNet |
|---|---|
 |  |
 |  |
PlainNet에선 $n=9$인 경우의 모델이 $n=3$인 모델보다 손실이 더 큰데, 레이어층이 깊어질수록 학습 오차가 높아지는 저하 현상이 발견되는 것을 볼 수 있다.
이와는 반대로 ResNet의 경우 레이어 층이 깊어질 수록 이러한 저하 현상이 해결되고, 정상적으로 학습이 되었음을 확인할 수 있다.
찌라시
즉, 레이어 층이 깊어질 수록 무조건 좋다는 아니지만, Residual learning을 통해서 층을 깊게 쌓아도 학습이 가능하게 된다는 점에서 의의가 있다.