Generative Modeling by Estimating Gradients of the Data Distribution
Generative Modeling by Estimating Gradients of the Data Distribution
Generative Modeling by Estimating Gradients of the Data Distribution
Introduction
이 논문에서는 생성형 모델에서 우도함수 기반 (ex. VAE) 이나 Adversarial 훈련 프레임워크 (ex. GAN) 에 기반하지 않고, (Stein) Score 이라는 개념을 사용하여 학습하고 샘플링하는 방법을 설명한다.
한번 드가보자.

Score-based Generative Modeling
일단 먼저 Score라는게 무엇이냐, 임의의 분포 $p(x)$ 의 Score은 $\nabla_{x} \log p(x)$ 로 정의되며, $\log p(x)$ 의 값이 가장 큰 방향, 즉, 최빈값(Mode)를 향하는 방향을 가리키는 벡터장을 의미한다.
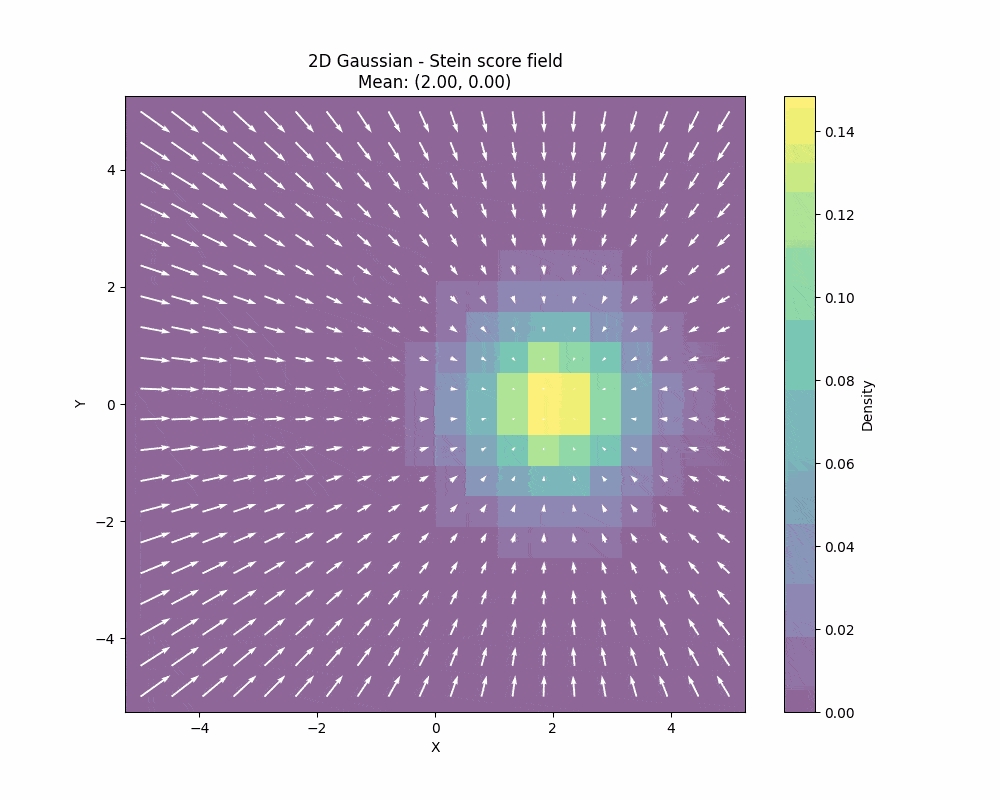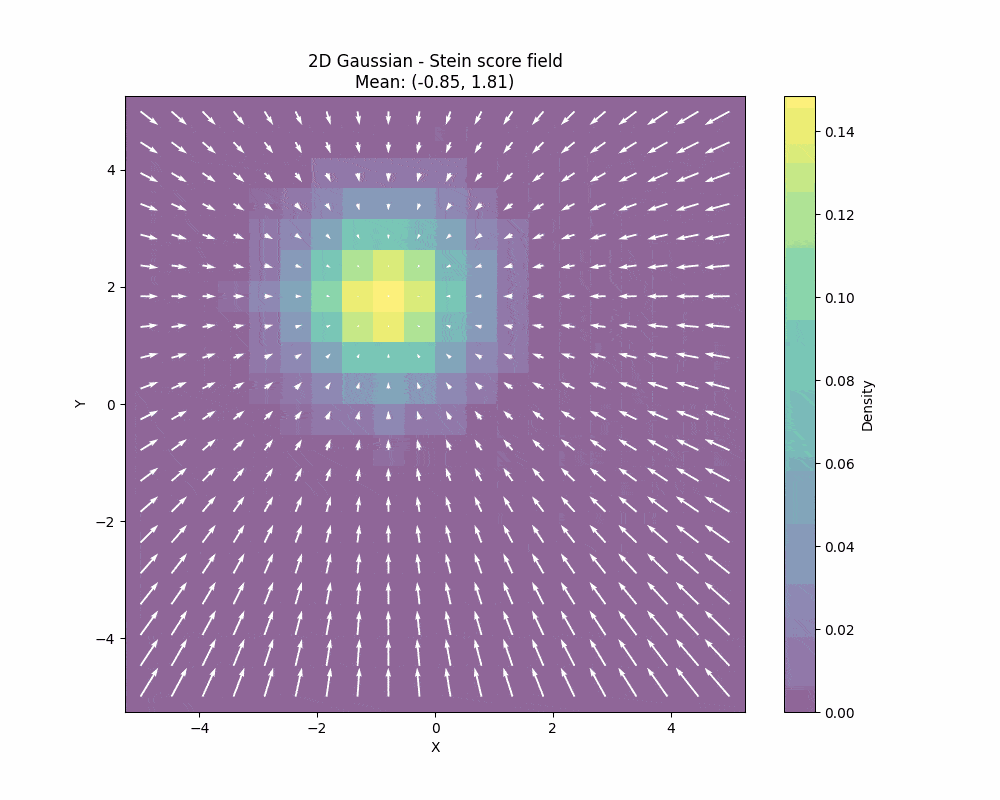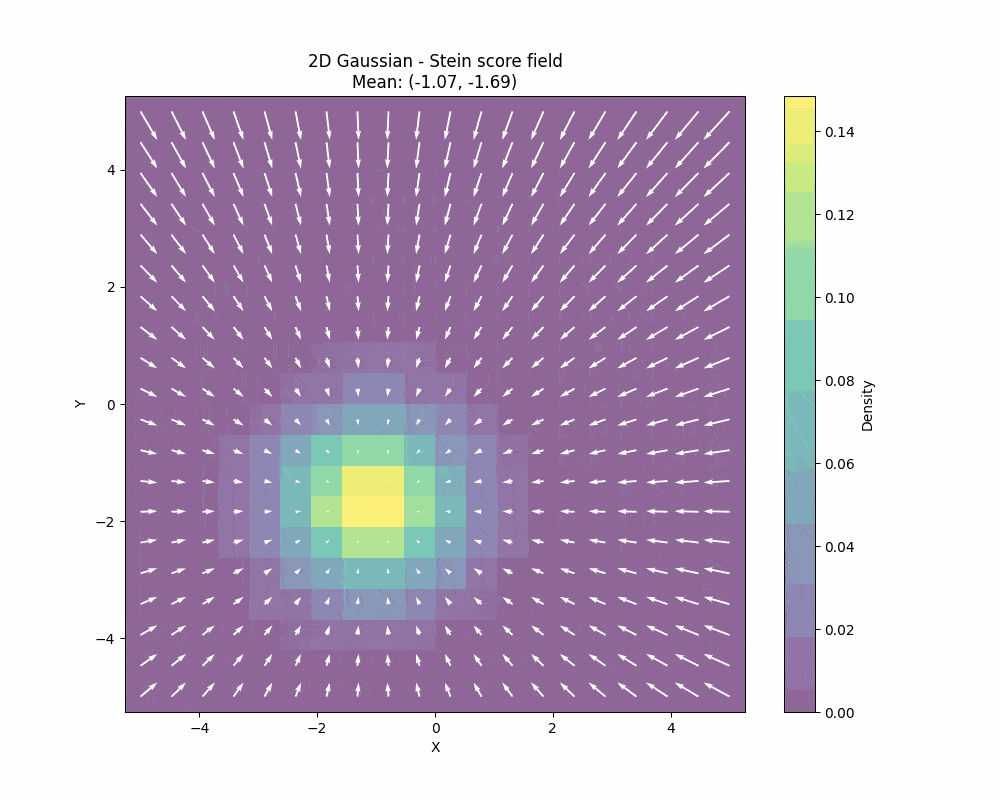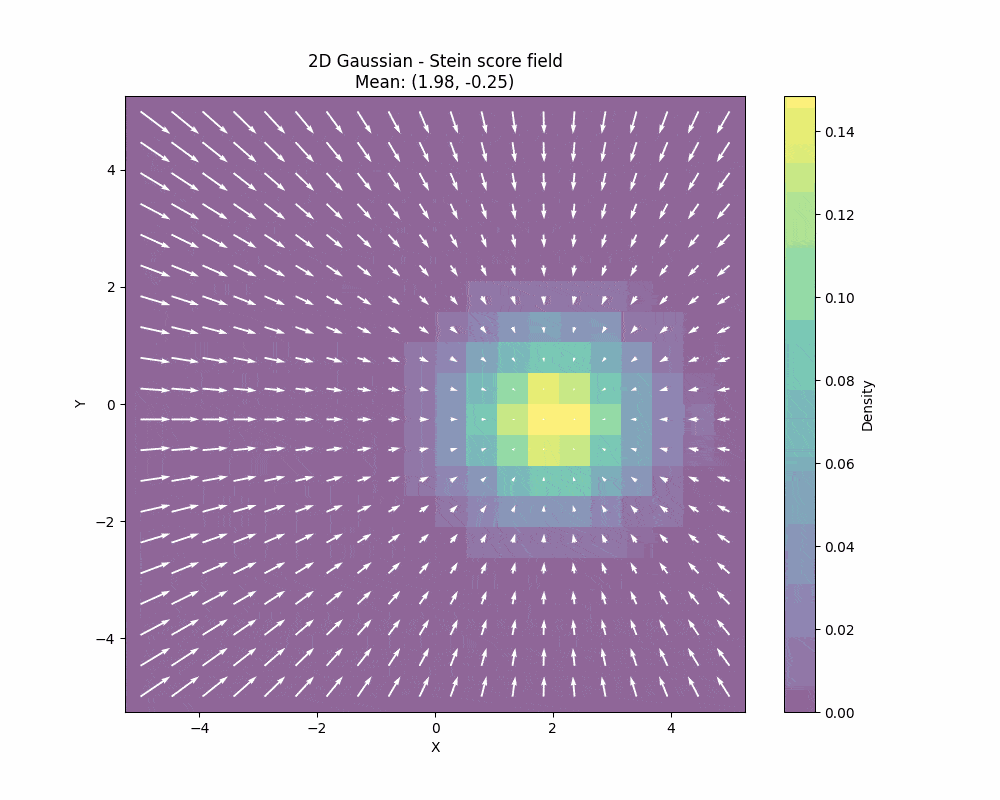 벡터장 예시
벡터장 예시
위 사진은 이 형님의 블로그에서 쌈뽕해서 가져와봤다… https://blog.christianperone.com/2024/11/the-geometry-of-data-part-ii/
아무튼튼 이러한 Score 값, 즉, 로그 확률 밀도의 최빈값을 향하는 기울기를 사용하여 기존 분포 $p(x)$ 를 유추할 수 있는데, 자세하게는 여기를 확인하자…
잡설은 뒤로 미루고 결론만 말하자면 이 논문에서의 우리의 목적은 이러한 $\nabla_{x} \log p(x)$ 를 직접적으로 근사하는 Score network $s_{\theta}$ 를 학습하는 것이다. 이제 차근차근 알아보자.
Score Matching for Score Estimation
Score network $s_{\theta}$ 를 학습시키기 위해서, 목적함수로 다음과 같은 Score Matching 을 사용한다.
\[\begin{align} L &= \frac{1}{2} \mathbb{E}_{p_{\text{data}}(x)}\left[\left|\left| s_{\theta}(x) - \nabla_{x} \log p_{\text{data}}(x) \right|\right|_{2}^{2}\right] \\ &\cdots \quad \text{서커스 시작} \\ &= \mathbb{E}_{p_{\text{data}}(x)}\left[\text{tr}(\nabla_{x} s_{\theta}(x)) + \frac{1}{2} ||s_{\theta}(x)||_{2}^{2} \right] \end{align} \tag*{1}\]서커스 과정은 여기를 확인하자.
위 식에서 $\nabla_{x} s_{\theta}(x)$ 은 $s_{\theta}(x)$ 의 Jacobian 이다.
원래 식에 있던 우리가 알고자했지만 알지 못하는 $\nabla_{x}\log p_{\text{data}}(x)$ 가 어디론가로 사라지고, 모델이 에측한 값만을 사용해서 최적화를 진행할 수 있게 되었다. 신기하다.
아무튼 이 식을 최소화 한다는 것은, 각 항을 살펴보면, 전자의 $\text{tr}(\nabla_{x} s_{\theta}(x))$ 의 벡터장의 대각합이 나타내는 것은 Score 값들의 발산을 의미한다. 이 값들이 양의 값일 때 Score, 즉 화살표들이 사방으로 뿜어져 나가는 형태가 되고, 음의 값일 때 블랙홀 처럼 사방의 화살표들이 현재 점 $x$ 로 빨려들어오는 형태가 된다. 즉, 모든 화살표들이 실제 데이터가 존재하는 방향을 향하도록 하는 역할을 한다.
후자는 Score 값 자체를 최소화한다고 볼 수 있는데, 벡터 장의 화살표들이 최빈값에 도달했을 때, Score 값이 0이 되게끔 하여, 각 Score 값이 무한하게 음수가 되는 것을 방지한다.
그래서 이 두 항의 앙상블로, 모델 $s_{\theta}$ 이 데이터가 있는 곳으로 Score 를 향하게 하되, 최빈값에 도착하면 Score 값이 0이 되게끔 하는 실제 데이터의 Score 벡터장 $\nabla_{x} \log p_{\text{data}}(x)$ 의 근사 벡터장을 학습하게끔 한다.
여기서 앞선 항 $\text{tr}(\nabla_{x} s_{\theta}(x))$ 을 계산하는게 거시기 한데, $x \in \mathbb{R}^{d}$ 에 대해서, $\nabla_{x} s_{\theta}(x)$ 을 계산하면 $d \times d$ Jacobian 행렬이 나온다. $\text{tr}(\nabla_{x} s_{\theta}(x))$ 이를 통해서 또 $d$ 개를 더해야 한다. 아무튼 만약 이미지 데이터를 예시로, $32 \times 32$ 크기의 RGB 채널 이미지라고 해도, $32 \times 32 \times 3 = 3072$ 번의 미분 계산이 필요하다.
아무튼 그래서 이러한 점을 어떻게 다루는지 알아보자.
Denoising score matching
Denoising score matching 은 $x$ 에 바로 score matching 을 사용하지 않고, $x$ 에 노이즈를 추가하여, 노이즈가 낀 $x$ 에 대해 Score matching 을 수행하는 것이다. 이때 이 노이즈는 $q_{\sigma}(\tilde{x}|x)$ 로 정의되며, 노이즈 낀 분포는 $q_{\sigma}(\tilde{x}) = \int q_{\sigma}(\tilde{x}|x) p_{\text{data}}(x)\,dx$ 로 정의된다. 따라서 노이즈를 추가한 후의 목적 함수는 다음과 같다.
\[\frac{1}{2}\mathbb{E}_{q_{\sigma}(\tilde{x}|x)p_{\text{data}}(x)}\left[ ||s_{\theta}(\tilde{x}) - \nabla_{\tilde{x}} \log q_{\sigma}(\tilde{x}|x)||_{2}^{2} \right]\]서커스 과정은 여기를 확인하자..
아무튼 이 목적 함수를 최적화하는 파라미터 $\theta^{\star}$ 에 대해서, $s_{\theta^{\star}}(\tilde{x}) = \nabla_{\tilde{x}} \log q_{\sigma}(\tilde{x})$ 가 최적의 모델이 된다. 왜 $\nabla_{\tilde{x}} \log q_{\sigma}(\tilde{x}|x)$ 이 값을 예측하는게 아닌지는 여기를 확인하자…..
여기서 추가되는 노이즈가 아~주 적은, 미미한 경우, 즉 노이즈를 추가하더라도 원본 데이터와 충분히 비슷한 경우에만 $\nabla_{\tilde{x}} \log q_{\sigma}(\tilde{x}) \approx \nabla_{\tilde{x}} \log p_{\text{data}}(\tilde{x})$ 를 만족한다.
Sliced score matching
Sliced score matching은 $\text{tr}(\nabla_{x} s_{\theta}(x))$ 에 무작위 투영 연산을 수행하여 근사하는 방식이다. 즉, 다음과 같다.
\[\mathbb{E}_{p_{v}}\mathbb{E}_{p_{\text{data}}}\left[ v^{T}\nabla_{x} s_{\theta}(x)v + \frac{1}{2}\|s_{\theta}(x)\|_{2}^{2}\right]\]이때 $p_{v}$ 는 무작위 백터의 다변량 표준 정규 분포와 같은 간단한 분포이다.
$v^{T}\nabla_{x} s_{\theta}(x)v \to v^{T}(\nabla_{x} s_{\theta}(x)v)$ 여기서 $\nabla_{x} s_{\theta}(x)v$ 이 부분이 $d \times d$ 행렬과 $d \times 1$ 벡터의 곱셈으로, Jacobian-Vector Product, JYP 의 형태이다. 이를 통해서 앞서 살펴봤던 계산이 힘들었던 이유인 높은 차원의 입력 데이터에 대해서 $d \times d$ 연산을 수행할 필요 없이, $d \times 1$ 크기의 $\nabla_{x} s_{\theta}(x)v$ 를 바로 계산함으로써 연산량을 줄인다. 이를 위해서 Forward-mode Auto-differentiation 이 사용되는데, 이 방식은 역전파처럼 결과값에서 시작해서 입력값 방향으로 미분을 전파하는게 아닌, 입력값에서 출력값 방향으로 원본값과 미분값을 동시에 흘려보내는 방식이다. 예를 들어서…
처음에 입력 데이터 $x$ 를 넣을 때, $x$ 의 미분 방향 변수에 샘플링한 무작위 벡터 $v$ 를 넣는다. 그러면
- 입력: $x$
- 미분 입력: $\dot{x} = v$
여기서 신경망들을 거치면서 덧셈, 곱셈 등등 수행이 될텐데, 그럴 때마다 미분값도 동시에 계산해 나간다. 그러면 최종 출력으로는 다음과 같다.
- 출력: $s_{\theta}(x)$
- 미분 출력: $\nabla_{x}s_{\theta}(x) \cdot \dot{x}$
이 미분 출력에 $v$ 만 추가로 내적해주면 $v^{T}\nabla_{x} s_{\theta}(x)v$ 가 계산된다.
앞선 방식과는 다르게 SLiced score matching 은 원본 데이터 $x$ 에 대한 score 을 추정하는데, 하지만 $v^{T}\nabla_{x} s_{\theta}(x)v$ 를 계산하는 연산을 추가로 필요로 한다는 점이 있다.
Sampling with Langevin Dynamics
Langevin Dynamics 는 다음과 같은 형태의 샘플링 과정이다.
\[\tilde{x}_{t} = \tilde{x}_{t-1} + \frac{\epsilon}{2}\nabla_{x} \log p(\tilde{x}_{t-1}) + \sqrt{\epsilon}z_{t}\]여기서 $\epsilon > 0$ 은 고정된 학습률(Step size)이고, 초기값 $\tilde{x}_{0} \sim \pi(x)$ 로 정의되는데 $\pi$ 는 사전 분포이다. 그리고 $z_{t} \sim \mathcal{N}(0,\mathbf{I})$ 이다.
- $\tilde{x}_{t-1}$: 현재 위치
- $\frac{\epsilon}{2}\nabla_{x} \log p(\tilde{x}_{t-1})$: 현재 위치에서, 분포의 최빈값의 방향
- $\sqrt{\epsilon}z_{t}$: 약간 최빈값 방향으로 무작정 가지 않고, 무작위 노이즈 값을 통해 각 스텝 $t$ 마다 정신산만한 착한 친구처럼 아주 살짝 미세하게 무작위로 요동침. 이를 통해서 최빈값에 다다르더라도 요리조리 다니며 다른 최빈값으로 이동할 수 있음. 얘 덕분에 지나온 궤적이 분포 $p(x)$ 를 나타내는 느낌
마지막 항 $\sqrt{\epsilon}z_{t}$ 이게 설명이 살짝 거시기한데, 이 항이 없다면, 결국 초기 위치 $x_{0}$ 에서 샘플링을 시작하여, 분포의 최빈값의 방향으로 곧장 향하게만 될 것이다. 그리고 최빈값에 도착하면 더 이상 위치 변화가 없을 텐데 ($\nabla_{x} \log p(\tilde{x}_{t-1}) \approx 0$), 그냥 데이터 분포의 한 점으로 수렴하여 분포를 묘사한다는 것이다. 즉, 초기 위치가 다르더라도 같은 점으로 수렴해버려, 결국 어느 초기 위치에서 시작하든 아래와 같이 동일한 데이터만 샘플링될 것이다.
 | | |
|---|---|---|
| | |
최종 위치가 국소적 최대값(Local Maximum) 이나 안장점(Saddle point) 인 경우에도 멈춰설 수 있고…. 아 그냥 저 항이 없으면 확률 분포를 반영하지 못한다는 것이다.
식을 보면 모델 $s_{\theta}$ 이 예측할 Score $\nabla_{x} \log p(\tilde{x}_{t-1})$ 만을 사용해서 $p(x)$ 에서 샘플링을 수행할 수 있음을 알 수 있는데, $\epsilon \to 0$, $T \to \infty$ 일 때, $\tilde{x}_{T}$ 의 분포는 $p(x)$ 와 같아진다.
$\epsilon > 0$, $T < \infty$ 의 경우엔 그만큼 오차가 심해질텐데, 이를 교정하기 위해 Metropolis–Hastings algorithm 란걸 사용할 수 있지만, 논문에서는 딱히 안써도 된다고 한다.
Challenges of Scores-based Generative Modeling

출세하고 성공의 길인 줄 알았는데 아쉽게도 풀어야할 두 개의 족쇄가 남아있었다. 어떤건지 알아보자…
The manifold hypothesis
일단 먼저 대부분의 데이터들은 거대한 고차원 공간 속에서 아주 작은 저차원 매니폴드(Manifold) 에만 몰려있다. (이를 Manifold Hypothesis 라고 한다.) 그러니까 예를 들어서… 다양한 도로롱들이, 아니다. 그냥 $32 \times 32$ 크기 RGB 채널의 고양이 이미지를 예시로 들자면, 고양이 데이터는 $32 \times 32 \times 3 = 3072$ 차원의 공간에서의 부분 공간이다. 3채널의 $32 \times 32$ 로 나타낼 수 있는 이미지들에 대해서 고양이 이미지로 분류되는 비율이 얼마나 될까. 그냥 겁~나게 적다는 것이다.
이 때문에 2가지 문제가 생기는데, 먼저 Score $\nabla_{x} \log p_{\text{data}}(x)$ 를 정의할 수 없다는 것이다. 음.. 그러니까 이 거대한 우주에서 지구의 빛(Score, 그냥 흐린 눈으로 지구 빛이라고 하자.) 을 추적하여 지구 ($p_{\text{data}}$) 를 찾아야하는데, 우주는 겁~나게 넓으니까 저~ 먼 곳에서는 이 지구 빛을 볼 수 조차 없다. Score 값이 안보이는거다. 아무튼 내가 이해한 바는 이런데.. 계속 짱구 돌려보다가 나중에 수정하겠다..
짱구를 굴려서 추가해보자면.. 데이터가 3차원 공간 속의 선이나 면과 같은 (2차원 매니폴드) 에만 존재한다면, 이를 벗어난 공간에서는 데이터의 확률 밀도가 0이 된다. $\log 0$ 이 정의되지 않으니 당연히 그 미분값도 정의가 안될테고…
그러니까 다시 말하면, $\nabla_{x} \log p_{\text{data}}(x) = \frac{\nabla_{x} p_{\text{data}}}{p_{\text{data}}}$ 로 정의되는데, 이 매니폴드와 멀리 떨어지면 $p_{\text{data}} \approx 0$ 이 되어서, $\frac{\nabla_{x} p_{\text{data}}}{p_{\text{data}}}$ 이게 정의가 되지 않는 것이다.
…또 다른 문제는 앞서 살펴본 우리의 목적함수에 대해서, $p_{\text{data}}$ 의 Support 가 전체 공간일 때만 일관된 Score 값을 제공하며, 저차원 매니폴드에 있다면 그렇지 않다는 것이다.
여기서 분포의 Support 는, $p(x) > 0$, 즉, 데이터가 존재하는 영역을 말한다. 여기서 매니폴드는 이러한 Support 가 가지는 저차원 기하학 구조를 말한다… 아 뭔가 딱 감올 것 같은데 거시기하다. 나중에 제대로 다뤄보겠다..

그래서 논문 저자 형님들이 이 족쇄가 어떤 영향을 주는지 실험해본 결과, 위 사진의 왼쪽과 같다. Sliced score matching 을 통해 학습을 진행했는데, 손실값이 감소하다 막 불규칙하게 요동치고 난리도 아니다.
오른쪽은 소량의 가우시안 노이즈를 전체 공간에 추가하여, 노이즈가 섞인 데이터에 대해 동일하게 학습을 진행한 것이다. 보다시피 학습이 야무지게 수렴하는 것을 볼 수 있다. 여기서 가우시안 노이즈는 $\mathcal{0, 0.0001}$ 로 진짜 엄~청 소량인데, 그럼에도 저렇게 전혀 다른 결과가 나왔다는 것이다.
Low data density regions
두 번째 문제는, 데이터 자체가 부족한 부분의 경우, 이 부분의 Score 값의 부족으로, 정확한 Score matching 을 수행하기 어렵다는 것이다.

위 사진은 논문의 저자들이 이를 확인하기 위해 $p_{\text{data}} = \frac{1}{5}\mathcal{N}((-5,-5), \mathbf{I}) + \frac{4}{5}\mathcal{N}((5,5), \mathbf{I})$ 형태의 두 가우시안의 혼합 분포의 Score 을 추정한 것이다. 왼쪽이 실제 $p_{\text{data}}$ 이고, 오른쪽이 우리가 추정한 $s_{\theta}(x)$ 이다. 그리고 사진에서 주황색 영역이 데이터가 존재하는 부분으로, 색이 진할수록 높은 밀도를 가진다. 오른쪽 사진을 보면 알 수 있듯이, 데이터가 밀집된 빨간 점선 내부의 영역에서는 Score 가 나름 잘 추정됐지만, 빨간 점선 외부에서는 Score 들이 왼쪽처럼 밀집된 곳으로 바로 향하지 않고 약간 틀어진 곳을 향하거나, 중앙부분에서 $0$ 에 가까워지는 식으로 안정적이지 못한 것을 볼 수 있다.
앞서 목적함수를 다시 상기해보면,
\[L = \frac{1}{2} \mathbb{E}_{p_{\text{data}}(x)}\left[\left|\left| s_{\theta}(x) - \nabla_{x} \log p_{\text{data}}(x) \right|\right|_{2}^{2}\right]\]결국 목적함수는 $p_{\text{data}}(x)$ 에 대해서만 기댓값이 걸려있다. 데이터가 거의 존재하지 않는 주황영역 밖 부분 $p_{\text{data}}(x) \approx 0$ 은 예측한 Score 값이 틀리든 말든 오차가 거의 $0$ 으로 계산된다. 즉, 모델 $s_{\theta}$ 은 이런 데이터가 거의 없는 부분에서의 Score 예측이 전체 손실에 기별도 안가니 그냥 학습을 안하게 되는 것이다.
또한, Langevin dynamics 는 앞선 예시의 혼합 분포에서, 각 분포의 가중치를 반영하지 못한다. 그러니까 앞선 가우시안 분포가 $p_{\text{data}} = \pi p_{1}(x) + (1-\pi)p_{2}(x)$ 이런 형태였고, 여기서 $p_{1}(x), p_{2}(x)$ 는 Support 영역이 겹치지 않는 정규화된 분포라고 하자.
$p_{1}(x)$ 의 Support에서의 Score 값을 계산해보면, $\nabla_{x} \log p_{\text{data}}(x) = \nabla_{x}(\log \pi + \log p_{1}(x)) = \nabla_{x} \log p_{1}(x)$ 이 되고, $p_{2}(x)$ 의 Support 에서 Score 값은 $\nabla_{x} \log p_{\text{data}}(x) = \nabla_{x}(\log (1-\pi) + \log p_{2}(x)) = \nabla_{x} \log p_{2}(x)$ 가 된다. 즉, 두 분포의 가중치 $\pi$ 가 반영이 되지 않은 것이다.
앞선 예시를 다시 살펴보면,
두 분포 $p_{1}(x), p_{2}(x)$ 의 Support 사이에 low density region 이 위치하는 것을 볼 수 있는데, 이러한 low density region 이 이러한 두 분포의 가중치 반영을 더 방해한다고 할 수 있다. 앞서 Langevin dynamics 식에서,
\[\tilde{x}_{t} = \tilde{x}_{t-1} + \frac{\epsilon}{2}\nabla_{x} \log p(\tilde{x}_{t-1}) + \sqrt{\epsilon}z_{t}\]여기서 $\sqrt{\epsilon}z_{t}$ 이 항을 통해서 최빈값에 도착하더라도 계속해서 전체 공간을 돌아다닐 수 있게끔 하는데, 다시 말해서 한 최빈값에 도착하더라도 계속해서 움직이며 나머지 다른 최빈값으로도 이동할 수 있게끔한다. 이 과정으로 각 분포의 가중치를 반영할 수 있는데, 다른 최빈값으로 이동하는 과정에 low density region 에 다다르게 되면, 이 영역을 가로질러 지나가는게 굉장히 어렵기 때문이다. 물론 기적의 확률로 지나칠 수도 있기야 하겠지만, 이를 위해선 매우 작은 학습률 ($\epsilon \to 0$) 과 겁~나게 많은 스텝 ($T \to \infty$) 가 요구될 것이다.

위 사진은 앞선 예시 $p_{\text{data}} = \frac{1}{5}\mathcal{N}((-5,-5), \mathbf{I}) + \frac{4}{5}\mathcal{N}((5,5), \mathbf{I})$ 에 대해서 테스트를 해본건데, 첫번째 사진이 실제 $p_{\text{data}}$ 이고, 두번째가 Langevin dynamics 를 통해 샘플링을 진행한 결과이다. 사진을 보면 알 수 있듯이, $p_{\text{data}}$ 에서의 두 최빈값의 가중치를 Langevin dynamics 에서 반영을 하지 않고 있다. 물론 앞서 말했듯이 $\epsilon \to 0$, $T \to \infty$ 이면 가능이야 하겠지만.. 엄청 오래걸릴 것이다..
Noise Conditional Score Networks, NCSN

앞에서 솰라솰라 어쩌고 저쩌고 했는데, 그냥 가우시안 노이즈를 추가하는 걸로 해결가능하다.
앞서 살펴봤던 manifold hypothesis 문제에 대해선 가우시안 노이즈를 전체 공간에 대해 추가하면, Score 들이 잘 정의되어 학습이 안정적이게 된다는 것을 확인했다 ($p_{\text{data}} > 0$ 이 되므로).
low density region 에 대해서도 충분히 큰 가우시안 노이즈가 추가되면 Low density region이 그만큼 영역이 작아질 것이고, 최빈값 부근은 델타함수같은 모양에서 좀더 완만한 종모양의 형태가 되어 뭐랄까…살짝 기압이 내려가는 느낌이랄까, 그냥 밀도가 낮아지게 된다. 그러면 Score 값 추정도 전체 공간에서 안정적으로 될 것이다.
그래서 이 논문에선 이러한 섞인 노이즈의 양에 따라 여러 레벨로 나누고, 각 레벨의 노이즈를 조건부로 두는 하나의 모델을 학습한다 (DDPM 에서 각 스템 $t$ 에 개별 모델을 학습하지 않는 것처럼 각 노이즈 레벨에 따른 개별 모델들이 아닌 파라미터를 공유하는 하나의 모델을 학습한다).
샘플링 과정은 이에 맞춰서 가장 높은 레벨의 노이즈가 섞인 분포부터 Langevin dynamics 과정을 시작해서, 점차 노이즈 레벨을 낮춰가며 원래 분포애 가까워질 때까지 이를 반복한다. 이를 Annealing Langevin dynamics 라고 하는데, 좀따 자세히 알아보자.
Training
먼저 노이즈가 섞인 데이터 분포를 다음과 같이 정의한다.
\[q_{\sigma}(\tilde{x}) = \int p_{\text{data}}(x)q_{\sigma}(\tilde{x}|x) \, dx = \int p_{\text{data}}(x) \mathcal{N}(\tilde{x} | x, \sigma^{2}\mathbf{I}) \, dx\]이때 $\set{\sigma_{i}}_{i=1}^{L}$ 은 노이즈 레벨로, $\sigma_{1} > \sigma{2} > \cdots > \sigma_{L}$ 을 만족한다. $\sigma_{1}$ 은 앞서 살펴본 Manifold Hypothesis 와 Low Density Regions 문제를 해결할 수 있을 정도로 충분히 크게 설정하고, $\sigma_{L}$ 은 기존 데이터의 영향을 최대한 덜 주는 정도로 설정된다.
Denoising Score Matching 의 경우, 각 $\sigma_{i}$ 에 대해 목적함수는 다음과 같다.
\[\begin{align} \ell(\theta; \sigma_{i}) &= \frac{1}{2} \mathbb{E}_{p_{\text{data}}(x)}\mathbb{E}_{\tilde{x} \sim \mathcal{N}(\tilde{x} | x, \sigma_{i}^{2}\mathbf{I})} \left[\left|\left|s_{\theta}(\tilde{x}, \theta) - \nabla_{\tilde{x}} \log q_{\sigma_{i}}(\tilde{x}|x) \right|\right|_{2}^{2} \right] \\ &= \frac{1}{2} \mathbb{E}_{p_{\text{data}}(x)}\mathbb{E}_{\tilde{x} \sim \mathcal{N}(\tilde{x} | x, \sigma_{i}^{2}\mathbf{I})} \left[\left|\left|s_{\theta}(\tilde{x}, \theta) + \frac{\tilde{x} - x}{\sigma_{i}^{2}} \right|\right|_{2}^{2} \right] \end{align}\]모든 $\set{\sigma_{i}}_{i=1}^{L}$ 에 대한 목적함수는 다음과 같다.
\[\mathcal{L}(\theta; \set{\sigma_{i}}_{i=1}^{L}) = \frac{1}{L} \sum_{i=1}^{L} \lambda(\sigma_{i}) \ell(\theta; \sigma_{i})\]이때 $\lambda(\sigma_{i}) > 0$ 는 각 $\ell(\theta; \sigma_{i})$ 에 대한 가중치로, 논문에서는 $\lambda(\sigma_{i}) = \sigma_{i}^{2}$ 로 설정하였는데, 이 형님들이 $\lambda(\sigma_{i}) \ell(\theta; \sigma_{i})$ 의 값이 모든 $\set{\sigma_{i}}_{i=1}^{L}$ 값에 대해서 어느정도 비슷한 크기로 설정하는게 이상적이라고 생각하셨다. 그래서 살펴본 결과 이 손실 함수가 최적이 될 때 $||s_{\theta}(\tilde{x}, \theta)||_{2} \propto \sigma^{-1}$ 임을 알아냈고, $\lambda(\sigma_{i}) = \sigma_{i}^{2}$ 로 설정해서,
\[\lambda(\sigma_{i}) \ell(\theta; \sigma_{i}) = \frac{1}{2} \mathbb{E}_{p_{\text{data}}(x)}\mathbb{E}_{\tilde{x} \sim \mathcal{N}(\tilde{x} | x, \sigma_{i}^{2}\mathbf{I})} \left[\left|\left|\sigma s_{\theta}(\tilde{x}, \theta) + \frac{\tilde{x} - x}{\sigma_{i}} \right|\right|_{2}^{2} \right]\]이 되게끔 했다. 이렇게 하면 $\frac{\tilde{x} - x}{\sigma_{i}} \sim \mathcal{N}(0, \mathbf{I})$, $|\sigma s_{\theta}(\tilde{x}, \theta)|_{2} \propto 1$ 이 되어, $\lambda(\sigma_{i}) \ell(\theta; \sigma_{i})$ 가 $\sigma_{i}$ 에 의존하지 않고, 비슷비슷한 크기를 가지게 된다. 이를 통해서 특정 노이즈 레벨에서만 학습을 집중하지 않고, 고르게 학습을 진행할 수 있게 된다.
Annealed Langevin dynamics
앞서 샘플링을 Annealed Langevin dynamics 를 사용한다고 했는데, 과정은 다음과 같다.

먼저 앞선 Langevin Dynamics와 거의 동일하게, $\epsilon > 0$, $T$ 는 각 레벨에서의 Langevin dynamics 과정의 단계 수, 그리고 초깃값 $\tilde{x}_{0} \sim \pi(x)$ 로 정의된다.
먼저 $\sigma_{1}$ 레벨에서 시작해서, 다음과 같이 위치 갱신을 $T$ 번 반복한다.
\[\tilde{x}_{t} = \tilde{x}_{t-1} + \frac{\alpha_{i}}{2} s_{\theta}(\tilde{x}_{t-1}, \sigma_{i}) + \sqrt{\alpha_{i}} z_{t}\]이때 $z_{t} \sim \mathcal{N}(0, \mathbf{I})$이고, 기존 Langevin Dynamics의 학습률이었던 $\epsilon$ 이 $\alpha_{i}$ 로 바뀌었는데, 이 새로운 학습률은 $\alpha_{i} = \frac{\epsilon \cdot \sigma_{i}^{2}}{\sigma_{L}^{2}}$ 로 정의된다. 즉, $\sigma_{1}$ 레벨에서의 초기 학습률이 매우 크지만, 노이즈 레벨이 낮아질수록 학습률이 작아지며, 최종 $\sigma_{L}$ 레벨에선 학습률이 $\epsilon$ 이 되어 정교해진다.
아무튼 이렇게 초깃값 $\tilde{x}_{0}$ 에서 $\tilde{x}_{T}$ 까지, $\sigma_{1}$ 레벨에서 $T$ 번동안 Langevin dynamics 를 진행하여 도착한 최종 위치가 $\tilde{x}_{T}$ 가 다음 $\sigma_{2}$ 레벨에서의 초기 위치 $\tilde{x}_{0}$ 가 되고, 학습률을 다시 정의하여 같은 과정을 반복한다. 이렇게 반복하고 반복해서, $\sigma_{L}$ 레벨에서의 $\tilde{x}_{T}$ 가 Annealed Langevin dynamics 알고리즘이 생성한 최종 샘플이 된다. 즉, $q_{\sigma_{L}}(\tilde{x}_{T}) \approx p_{\text{data}}(\tilde{x})$ 이 된다.
그러니까 처음에 큰 노이즈를 줘서 데이터들이 어디에 모여있는지 대략적으로 찾고, 노이즈를 점차 줄여가며 좀 더 세세하게 찾는 과정인 것이다.
이렇게 큰 노이즈 레벨 부터 시작해서 점차 노이즈 레벨을 낮춰가며 Langevin dynamics 을 수행하면, 모델이 추정하는 Score 값이 더 정확해지고, 앞서 두 최빈값의 가중치를 반영하는걸 더 빨리 수행할 수 있는데, $q_{\sigma_{i-1}}(x)$ 의 High density regions 에서 샘플링될 가능성이 크다는건, $q_{\sigma_{i}}(x)$ 에서도 High density regions 에서 샘플링될 가능성이 크다는 것과 같다. 왜냐하면 $q_{\sigma_{i-1}}(x) \approx q_{\sigma_{i}}(x)$ 와 같이 두 분포는 아주 미세한 가우시안 노이즈의 차이만 있기 때문이다. $q_{\sigma_{i-1}}(x)$ 가 High density regions 에 있다는건 그만큼 정확한 Score 값을 반영하여 Langevin dynamics 을 통해 정확한 $\tilde{x}_{T}$ 를 찾는다는 것이고, 이는 $q_{\sigma_{i}}(x)$ 의 초깃값으로서 알맞다는 것이다.
여기서 학습률을 다르게도 정의할 수 있지만, 논문에서 $\alpha_{i} = \frac{\epsilon \cdot \sigma_{i}^{2}}{\sigma_{L}^{2}} \propto \sigma_{i}^{2}$ 로 정의한 이유는, SNR(Signal-to-Noise Ratio) $\frac{\alpha_{i}s_{\theta}(x,\sigma_{i})}{2\sqrt{\alpha_{i}}z}$ 를 일정하게 맞추기 위해서이다.
SNR은 앞서 살펴본 $\tilde{x}_{t} = \tilde{x}_{t-1} + \frac{\alpha_{i}}{2} s_{\theta}(\tilde{x}_{t-1}, \sigma_{i}) + \sqrt{\alpha_{i}} z_{t}$ 의 식에서 2, 3번째 항의 비율임을 알 수 있는데, 전자가 신호, 후자를 노이즈(잡음) 으로 생각할 수 있다.
\[\mathbb{E}\left[\left|\left| \frac{\alpha_{i}s_{\theta}(x,\sigma_{i})}{2\sqrt{\alpha_{i}}z} \right|\right|_{2}^{2}\right] \approx \mathbb{E}\left[\frac{\alpha_{i} \|s_{\theta}(x,\sigma_{i})\|_{2}^{2}}{4} \right] \propto \frac{1}{4} \mathbb{E}\left[\|\sigma_{i} s_{\theta}(x,\sigma_{i})\|_{2}^{2} \right]\]여기서 앞서서 손실 함수가 최적이 될 때 $||s_{\theta}(\tilde{x}, \theta)||_{2} \propto \sigma^{-1}$ 였음을 여기에 적용하면,
\[\mathbb{E}\left[\|\sigma_{i} s_{\theta}(x,\sigma_{i})\|_{2}^{2} \right] \propto 1 \implies \left|\left| \frac{\alpha_{i}s_{\theta}(x,\sigma_{i})}{2\sqrt{\alpha_{i}}z} \right|\right|_{2} \propto \frac{1}{4}\]즉, SNR이 $\sigma_{i}$ 에 의존하지 않는다. 다시 말해서 노이즈 레벨에 따라 SNR이 달라지지 않아, 특정 노이즈에선 최빈값으로 일직선으로 가고 다른 특정 노이즈에선 최빈값으로 이동하지 않고 사방으로 짱구마냥 날뛰지 않고, 모든 노이즈에 대해서 이 두 힘(?) 을 일정한 비율로 고정하여 일관된 텐션으로 이동할 수 있는 것이다.
위 사진은 앞선 $p_{\text{data}} = \frac{1}{5}\mathcal{N}((-5,-5), \mathbf{I}) + \frac{4}{5}\mathcal{N}((5,5), \mathbf{I})$ 의 예시를 다시 가져온건데, 3번째 사진이 바로 Annealed Langevin dynamics 를 통해 샘플링한 결과이다. 보면 일반적인 Langevin dynamics 와 달리, 두 최빈값의 가중치를 어느정도 야무지게 반영하고 있음을 알 수 있다.
주절주절 찌라시
그냥 개념 공부만 할려고 본거라서 따로 구현은 안했다. 절대 귀찮은게 아니다.

내가 잘못 이해한게 있을 수도 있는데, 일단 계속 공부해보다가 엥? 이다 싶으면 다시 수정하겠다..
역시나 의식의 흐름대로 작성하다보니 글 흐름이 거시하고.. 가독성은 개나 줘버렸는데.. 내가 보기에 이해되면 장땡이니까 상관없다. 그래도 혹시나 미안하다. 노력은 해보겠다..
추가 설명
Score matching
Score matching 에 대해 알아보기 전에, Energy-based Model, EBM 이란걸 아주 사알짝만 다뤄보자면…
어떠한 $p_{\text{data}}$ 분포가 있을 때, 이를 직관적으로 나타내기 쉬운 방법은 EBM 의 형태로 $p_{\text{data}}$ 를 근사하는 것이다. 즉,
\[p_{\text{data}} \approx p_{\theta}(x) = \frac{\exp(-f_{\theta}(x))}{Z} = \frac{\exp(-f_{\theta}(x))}{\int \exp(-f_{\theta}(x))\, dx}\]요런 식으로 $\theta$ 를 파라미터로 가지는 함수 $f_{\theta}(x)$ (에너지 함수 $E_{\theta}(x)$ ) 를 통해 기존 분포 $p_{\text{data}}$ 를 근사하는 방식으로, 에너지 함수는 데이터가 자연스러울 때, 낮은 값을 반환하고, 자연스럽지 않은 데이터일 때 높은 값을 반환한다.
아무튼 기존 Score matching은 이렇게 EBM 으로 근사한 모델의 Score, 즉, $-\nabla_{x} f_{\theta}(x)$ 를 기본 분포의 Score $\nabla_{x} p_{\text{data}}$ 와 같아지도록 파라미터 $\theta$ 를 조절하여 학습하는 것이다.
하지만 이 논문에서는 이렇게 에너지 함수의 Score을 계산하여 기존 데이터 분포의 Score에 근사하는 식으로 에너지 함수를 학습하는 것이 아니라, 에너지 함수고 뭐고 그냥 데이터 분포의 Score 자체를 근사하는 $s_{\theta}$ 를 근사하는 것이다.
\[\begin{align} \text{EBM} &: \nabla_{x} f_{\theta}(x) \approx \nabla_{x} p_{\text{data}}(x) \\ \text{score-based} &: s_{\theta}(x) \approx \nabla_{x} p_{\text{data}}(x) \end{align}\]아무튼 이를 통해서 $\nabla_{x} f_{\theta}(x)$ 과 같이 에너지 함수를 따로 미분하는 계산을 따로 필요로 하지 않는다.
Eq. 1
\[\begin{align} L &= \frac{1}{2} \mathbb{E}_{p_{\text{data}}(x)}\left[\left|\left| s_{\theta}(x) - \nabla_{x} \log p_{\text{data}}(x) \right|\right|_{2}^{2}\right] \\ &= \frac{1}{2} \int p_{\text{data}}(x)||s_{\theta}(x) - \nabla_{x} \log p_{\text{data}}(x) ||_{2}^{2} \, dx \quad \left(\mathbb{E}_{p_{\text{data}}(x)} = \int p_{\text{data}}(x)\,dx = 1 \right) \\ &= \frac{1}{2} \int p_{\text{data}}(x) \left[||s_{\theta}(x)||_{2}^{2} + ||\nabla_{x} \log p_{\text{data}}(x)||_{2}^{2} - 2s_{\theta}(x)^{T}\nabla_{x} \log p_{\text{data}}(x) \right] \,dx \\ &= \frac{1}{2} \int p_{\text{data}}(x) ||s_{\theta}(x)||_{2}^{2}\,dx + \frac{1}{2} \int p_{\text{data}}(x) ||\nabla_{x} \log p_{\text{data}}(x)||_{2}^{2} - \underbrace{\int p_{\text{data}}(x)s_{\theta}(x)^{T}\nabla_{x} \log p_{\text{data}}(x) \, dx}_{(1)} \\ (1) &\implies \int p_{\text{data}}(x) \sum_{i=1}^{d} \left(s_{\theta,i}(x) \nabla_{x_{i}}\log p_{\text{data}}(x) \right) \, dx \\ &= \sum_{i=1}^{d} \int s_{\theta,i}(x) \nabla_{x_{i}}p_{\text{data}}(x) \quad \left( \nabla_{x} \log p_{\text{data}}(x) = \frac{\nabla_{x} p_{\text{data}}(x)}{p_{\text{data}}(x)}\right)\\ &= \sum_{i=1}^{d}\left[ \underbrace{s_{\theta}p_{\text{data}}(x)|_{-\infty}^{\infty}}_{(2)} - \int p_{\text{data}}(x)\nabla_{x_{i}}s_{\theta,i}(x)\,dx\right] \quad \left( \int \nabla v \cdot u = vu|_{a}^{b} - \int v \cdot \nabla u \right) \\ &= - \sum_{i=1}^{d} \int p_{\text{data}}(x)\nabla_{x_{i}}s_{\theta,i}(x)\,dx \\ &= - \mathbb{E}_{p_{\text{data}}(x)}\left[ \sum_{i=1}^{d} \nabla_{x_{i}}s_{\theta,i}(x)\right] = -\mathbb{E}_{p_{\text{data}}(x)}[\text{tr}(\nabla_{x_{i}}s_{\theta}(x))] \\ \\ L &= \frac{1}{2} \int p_{\text{data}}(x) (s_{\theta}(x))^{2}\,dx + \frac{1}{2} \int p_{\text{data}}(x) (\nabla_{x} \log p_{\text{data}}(x))^{2} + \mathbb{E}_{p_{\text{data}}(x)}[\text{tr}(\nabla_{x_{i}}s_{\theta}(x))] \, dx \\ &= \frac{1}{2}\mathbb{E}_{p_{\text{data}}(x)}[(s_{\theta}(x))^{2}] + \underbrace{\frac{1}{2}\mathbb{E}_{p_{\text{data}}(x)}[(\nabla_{x} \log p_{\text{data}}(x))^{2}]}_{\text{$\theta$ 와 관련 없으므로 훈련 중 무시가능}} + \mathbb{E}_{p_{\text{data}}(x)}[\text{tr}(\nabla_{x_{i}}s_{\theta}(x))] \\ &= \mathbb{E}_{p_{\text{data}}(x)}[\text{tr}(\nabla_{x_{i}}s_{\theta}(x))] + \frac{1}{2}\mathbb{E}_{p_{\text{data}}(x)}[(s_{\theta}(x))^{2}] \end{align}\]Denoising score matching 서커스 과정
노이즈가 추가된 분포 $q_{\sigma}(\tilde{x}) = \int q_{\sigma}(\tilde{x}|x) p_{\text{data}}(x)\,dx$ 에 score matching 은 다음과 같다.
\[\begin{align} L &= \frac{1}{2}\mathbb{E}_{q_{\sigma}(\tilde{x})}\left[||s_{\theta}(\tilde{x}) - \nabla_{\tilde{x}}\log q_{\sigma}(\tilde{x})||_{2}^{2} \right] \\ &= \frac{1}{2} \int q_\sigma(\tilde{x}) \left\| s_\theta(\tilde{x}) - \nabla_{\tilde{x}} \log q_\sigma(\tilde{x}) \right\|_2^2 \, d\tilde{x} \\ &= \frac{1}{2} \int q_\sigma(\tilde{x}) \left\| s_\theta(\tilde{x})\right\|_2^2 \, d\tilde{x} - \underbrace{\int q_\sigma(\tilde{x})s_{\theta}(\tilde{x})^{T} \nabla_{\tilde{x}} \log q_\sigma(\tilde{x}) \, d\tilde{x}}_{(1)} + \text{$\theta$ 와 관련 없는 상수} \\ &\cdots\\ (1) &\implies \int q_\sigma(\tilde{x}) s_{\theta}(\tilde{x})^{T} \frac{\nabla_{\tilde{x}} q_{\sigma}(\tilde{x})}{q_{\sigma}(\tilde{x})} \, d\tilde{x} = \int s_{\theta}(\tilde{x})^{T}\nabla_{\tilde{x}} q_{\sigma}(\tilde{x}) \, d\tilde{x} \\ &= \int s_{\theta}(\tilde{x})^{T} \nabla_{\tilde{x}} \left(\int q_{\sigma}(\tilde{x}|x) p_{\text{data}}(x)\,dx\right) \, d\tilde{x} \\ &= \int \int p_{\text{data}}(x) \left(s_{\theta}(\tilde{x})^{T} \nabla_{\tilde{x}}q_{\sigma}(\tilde{x}|x) \right)\, dx \, d\tilde{x} \\ &= \int \int p_{\text{data}}(x) q_{\sigma}(\tilde{x}|x) \left( s_{\theta}(\tilde{x})^{T} \nabla_{\tilde{x}} \log q_{\sigma}(\tilde{x}| x) \right)\, dx \, d\tilde{x} \quad (\nabla q = q \nabla \log q) \\ &\cdots\\ L &= \frac{1}{2} \int q_\sigma(\tilde{x}) \left\| s_\theta(\tilde{x})\right\|_2^2 \, d\tilde{x} + \int \int p_{\text{data}}(x) q_{\sigma}(\tilde{x}|x) \left( s_{\theta}(\tilde{x})^{T} \nabla_{\tilde{x}} \log q_{\sigma}(\tilde{x}| x) \right)\, dx \, d\tilde{x} + C\\ &= \frac{1}{2} \int \int p_{\text{data}}(x) q_\sigma(\tilde{x}) \left\| s_\theta(\tilde{x})\right\|_2^2\, dx \, d\tilde{x} + \int \int p_{\text{data}}(x) q_{\sigma}(\tilde{x}|x) \left( s_{\theta}(\tilde{x})^{T} \nabla_{\tilde{x}} \log q_{\sigma}(\tilde{x}| x) \right)\, dx \, d\tilde{x} + C \\ &= \frac{1}{2} \int \int p_{\text{data}}(x) q_\sigma(\tilde{x})\left\| s_{\theta}(\tilde{x}) - \nabla_{\tilde{x}} \log q_{\sigma}(\tilde{x}| x) \right\|_2^2 \, dx \, d\tilde{x} \\ &= \frac{1}{2}\mathbb{E}_{q_{\sigma}(\tilde{x}|x)p_{\text{data}}(x)}\left[ ||s_{\theta}(\tilde{x}) - \nabla_{\tilde{x}} \log q\_{\sigma}(\tilde{x}|x)||_{2}^{2} \right] \end{align}\]Denoising score matching의 최적의 모델이 예측하는 값이 그렇고 그런 이유
\[\frac{1}{2}\mathbb{E}_{q_{\sigma}(\tilde{x}|x)p_{\text{data}}(x)}\left[ ||s_{\theta}(\tilde{x}) - \nabla_{\tilde{x}} \log q_{\sigma}(\tilde{x}|x)||_{2}^{2} \right]\]목적함수를 다시 살펴보면 $s_{\theta}(\tilde{x})$ 와 $\nabla_{\tilde{x}} \log q_{\sigma}(\tilde{x}|x)$ 사이의 평균 제곱 오차, MSE 의 형태이다.
여기서 우리의 모델 $s_{\theta}(\tilde{x})$ 이 입력값으로 노이즈가 낀 $\tilde{x}$ 만을 가지며, 원본 데이터 $x$ 를 따로 입력 받지 못하는데, 통계에서, $X$ 를 모른 채 주어진 $Y$ 만 보고 오차 제곱 기댓값을 최소화하는 최적의 함수 $f^{\star}(Y) = \arg\min_f \mathbb{E}[(f(Y) - X)^2]$ 을 구하면, 이 값은 항상 조건부 기댓값 $\mathbb{E}[X|Y]$ 가 된다.
이를 $q_{\sigma}(x, \tilde{x}) = q_{\sigma}(\tilde{x}|x)p_{\text{data}}(x)$ 를 통해 목적 함수에 대입하면, 특정 $\tilde{x}$ 가 주어졌을 때, 모델 $s_{\theta}(\tilde{x})$ 이 가질 수 있는 최적의 값 $s_{\theta^\star}(\tilde{x})$ 은 다음과 같이 $x$ 에 대한 조건부 기댓값 형태로 정의된다.
\[s_{\theta^\star}(\tilde{x}) = \mathbb{E}_{x \sim q_\sigma(x|\tilde{x})} \left[ \nabla_{\tilde{x}} \log q_{\sigma}(\tilde{x}|x) \right]\]이 식을 베이즈 정리를 통해 서커스를 진행하면 다음과 같다.
\[\begin{align} \mathbb{E}_{x \sim q_\sigma(x|\tilde{x})} \left[ \nabla_{\tilde{x}} \log q_{\sigma}(\tilde{x}|x) \right] &= \int q_{\sigma}(x|\tilde{x}) \nabla_{\tilde{x}}\log q_{\sigma}(\tilde{x}|x) \, dx\\ &= \int \frac{q_{\sigma}(\tilde{x}|x)p_{\text{data}}(x)}{q_{\sigma}(\tilde{x})} \frac{\nabla_{\tilde{x}}q_{\sigma}(\tilde{x}|x)}{q_{\sigma}(\tilde{x}|x)} \, dx\\ &= \frac{1}{q_{\sigma}(\tilde{x})} \int p_{\text{data}}(x) \nabla_{\tilde{x}}q_{\sigma}(\tilde{x}|x) \, dx\\ &= \frac{1}{q_{\sigma}(\tilde{x})}\nabla_{\tilde{x}} \underbrace{\int p_{\text{data}}(x) q_{\sigma}(\tilde{x}|x)}_{q_{\sigma}(\tilde{x})} \, dx\\ &= \frac{\nabla_{\tilde{x}} q_{\sigma}(\tilde{x})}{q_{\sigma}(\tilde{x})} = \nabla_{\tilde{x}} \log q_{\sigma}(\tilde{x}) \end{align}\]